چکیده در این مقاله نقش اطلاعات منبع باز (OSINT) را در مدیریت بحران مورد بررسی قرار میدهیم. بهطور ویژه، کاربرد سیستم اسخراج رسانهی آزمایشگاههای دریانوردی را در زمینهی عملیات امدادرسانی ارائه داده و از نمونههایی جهت نشان دادن مزایا و نقاط قوت سیستم (MM (Media Mining، استفاده میکنیم. در انتهای این مقاله، چالشهای آینده در تحقیقات و توسعهی این حوزه مورد اشاره قرار خواهند گرفت.
- مقدمه
دسترسی به اطلاعات موجود و بهروز در شرایط بحرانی یا رخداد فجایع، بسیار ضروری است. رخدادهای غیرمترقبه نیاز به درک عمیق و جامع نسبت به شرایط مربوط به بحران و عوامل درگیر در آن دارند تا سیاست مناسب اتخاذ و پاسخی بهموقع شکل گیرد. بهویژه در جامعهی اطلاعاتی امروز که بهسرعت درحال تغییر است، دسترسی به طیف وسیعی از منابع، شامل خوراکهای(فیدهای) وب، بلاگها، ایستگاههای رادیویی و تلویزیونی تا رسانههای اجتماعی میتواند در پاسخ به وقایع مهم نقش کلیدی ایفا کند.
منابع اطلاعاتی واقعی در ماهیت، کمیت، اعتبار و کیفیت بسیار متفاوتند. مقدار اطلاعات تولیدشده دائماً درحال رشد و تغییر کردن است. اطلاعات مدام در سرتاسر جهان به زبانهای مختلف و ازطریق طیفی از رسانهها، تولید میشود. اطلاعات جدید را بنگاههای خبری حرفهای یا اشخاص در اینترنت میگذارند، تلویزیون و ایستگاههای رادیویی منتشر میکنند یا در رسانههای اجتماعی نظیر توییتر و فیسبوک، به بحث گذاشته میشوند. مورد اخیر، بعد پیچیدهی دیگری به ترکیب منابع افزوده است. تمام منابع بالا، از جهات مختلفی مثل کیفیت یا زبان مورد استفاده با هم متفاوتند، و به انواع خاصی از پردازش نیاز دارند.
زبان، نقشی حیاتی در این پردازش ایفا میکند، چراکه اغلب یکی از مشکلات کلیدی در فجایعی با ابعاد جهانی این است که اطلاعات فقط از منابع محلی و به زبانهای بومی در دسترس هستند. برخی از فوریترین اطلاعات درمورد یک رخداد، ممکن است توسط خبرنگاران بومیِ کمتجربه تولید شده باشند و سابقهی اندکی از آنها موجود باشد که بتواند بهطور مستقل مورد بررسی قرار گیرد.
منابع باز، راهی ارزان، سریع و کارآمد جهت ارزیابی موقعیت آنهایی بهدست میدهند که در زمان یک بحران یا فاجعه، از آن تأثیر میپذیرند. این منابع، اطلاعات جمعآوری شده توسط منابع سنتی و رسمی را تکمیل، تقویت و حتی شکار میکنند. در بسیاری از موارد آنها امکان نقشهبرداری جغرافیاییِ رخدادها را فراهم میآورند، این مسئله بهخصوص درمورد جمعآوری اطلاعات با استفاده از منابع جمعی و برونسپاری صدق میکند. تعداد و تنوع منابع به سازمانها کمک میکند تا درستی و سطح اعتبار اطلاعات فراهمشده را تخمین بزنند، بدین ترتیب امکان بروز پاسخهای هدفمندتر و چرخهی تصمیمگیری کوتاهتر را در شروع واکنشهای اولیه فراهم میسازند. یکی از پیشفرضهای اساسی در مفهوم اطلاعات منبع باز این است که درواقع در منابعِ در دسترس عموم، موجودند و تنها کافی است جمعآوری شده و در اختیار اشخاص درست در زمان درست قرار گیرند. با اینوجود این وظیفهای مهم، بهشدت پیچیده و طاقتفرسا است.
این پسزمینهای است که آزمایشها در آن براساس سیستم رسانه کاویِ آزمایشگاههای سِیل (سیستم MM) انجام شدهاند. ویژگیهایی نظیر آنالیز ویدیویی، رونویسی سخنرانی و پیشرفتهای جستجوی مبتنی بر هستیشناسی با هم ترکیب شدند تا اطلاعاتی را فراهم سازند که بتوان آنها را در اختیار تحلیلگران و مرکز آگاهی از وضعیت قرار داد. جهتگیری ابتدایی سیستم بهسمت چندروشی ، چند زبانی و رفتارِ زمان واقعی گرایش داشته و میتواند درعرض چند روز گسترش یابد.
. شرح و توصیف سیستم
سیستم MM، یک سیستم پیمانهای با هدف پوشش کامل سیکل گردش کاریِ OSINT، از فاز ملزومات تا فازهای انتشار و بازخورد است. این سیستم، به متخصصان OSINT توانایی استخراج سریع آنالیزهای معنادار از دادههای بدون ساختار را، در اشکال متنوع و در میان زبانها و منابع مختلف، میدهد. تحلیلگران در طول کار خود، ازطریق فراهم ساختن ابزارهایی مورد حمایت قرار میگیرند که به آنها امکان کشف و جستجوی بصری حجم بالایی از دادهها را براساس مأموریتشان و زمینههای اطلاعات میدهد. انباشتگی و تراکم اطلاعات، منابع مربوطه در طول زمان و درمیان رسانهها، پایههایی را میسازند که تحلیلگران میتوانند براساس آنها وظایف خود را انجام دهند. این سیستم هرچند باز است، اما واقعاً سیستم کاملی است که میتواند در محیط موجود ادغام شود. هدف آن، پشتیبانی از فرآیندها و مراحل موجود است. گردشهای کاری موجود میتوانند برای کاربران، ابقا، اصلاح و تسهیل شوند.
سیستم MM متشکل از مجموعهای از فنآوریهاست که در قالب اجزا و مدلهایی بستهبندی و بهصورت سیستمی واحد برای استقرار پایان به پایان، ترکیب شده است. تعدادی از مجموعه ابزارها (toolkit) به کاربران نهایی اجازه میدهد تا مدلها را توسعه داده و اصلاح کنند تا به محیطی بسیار پویا، پاسخی انعطافپذیر بدهند. معماری کلی سیستم MM، از نوع سِرورمشتری است و امکان استقرار اجزای مختلف روی رایانهها و پایگاههای متنوع را فراهم میآورد. نیازی به حضور همهی اجزا و فنآوریها از همان ابتدا، وجود ندارد و موارد یادشده میتوانند بهتدریج درطول زمان اضافه شوند. ترکیب تغذیهکنندهها، نمایهسازها و سرورهای متعددی (که تغذیهکننده، نمایهساز و سرور رسانهکاو نیز خوانده میشوند) برای تشکیل یک سیستم کامل هم ممکن است.
شکل ۱ نگاهی اجمالی به اجزای سیستم MM و فعل و انفعال آنها دارد.
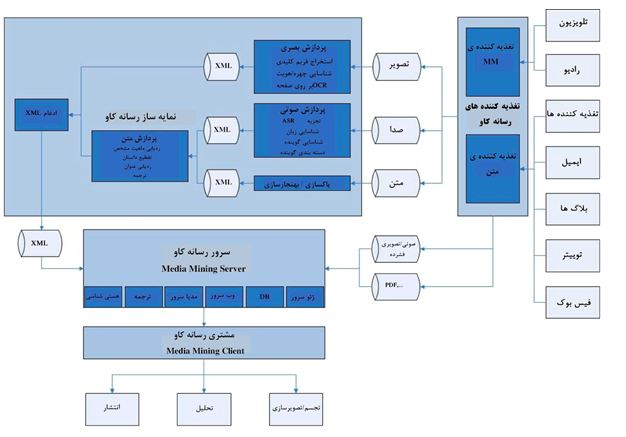
شکل ۱ ساختار کلی سیستم MM
الف. جریان داده بهطور کلی
دادهها ازطریق سیستمی موسوم به تعذیهکنندههای رسانهکاو وارد شده و سپس از یک سری مراحل پردازش عبور میکنند. دادههای چندرسانهای به مسیرهای پردازشی صوتی و تصویری تفکیک میشوند. دادههای صوتی، جهت شناسایی گوینده، واژگان بزرگ و تشخیص گفتار خودکار، وارد نمایهساز رسانهکاو (MMI) میشوند. برای دادههای تصویری، زنجیرهی پردازش شامل استخراج فریم کلیدی، ردیابی و شناسایی چهرهها و ردیابی متن و متعاقب آن تشخیص کاراکتر نوری (OCR) میشود. دادههای متنی، شامل متونِ فیدها و منابع رسانههای اجتماعی، و همچنین خروجی ارسال و دریافت اتوماتیک (ASR)، پیش از قرار گرفتن تحت پردازش ردیابی ماهیت مشخص و ردیابی عنوان، طی مراحل متعدد بههنجارسازی، پردازش میشوند.
اسناد حاصل از مسیرهای مجزا، در انتهای پردازش باهم ترکیب شده (ترکیب نهایی) و همراه با نسخهی فشردهای از فایلهای رسانهای اصلی، بر روی سرور رسانهکاو (MMS) بارگذاری میشوند، یعنی جایی که برای جستجوی متن کامل و بازیابی، در دسترس قرار میگیرند.
ب. تغذیه کنندههای رسانهکاو
تغذیهکنندهها، رابط ورودیِ سیستم MM را به دنیای خارج ارائه میدهند. برای ورودی صوتی یا ترکیب صوتی/تصویری، انواع فرمتها میتوانند از منابع خارجی جذب و توسط اجزای بعدی، پردازش شوند. در کار با ورودی متن، مثل دادههای صفحات وب، RSS-feedها، ایمیلها، وبلاگها و منابع رسانههای جمعی، تغذیهکنندههای مجزایی وجود دارند که اطلاعات مربوطه را از این منابع استخراج کرده و آنها را به اجزای پردازشگر متن میسپارند. تغذیهکنندههای اضافی برای منابع بیشتر، میتوانند با کمترین کوششی اضافه شوند. این مسئله، امکان پاسخ دادن سریعتر به محیطهای متغیر و منابع جدید داده را فراهم میسازد.
ج. نمایهساز رسانهکاو (MMI)
MMI در سیستم رسانهکاو (MM) ، برای قابلیتهای پردازش متن و صوت، نقش مرکزی را ایفا میکند. این نمایهساز از یک رشته فنآوری و مدلهای مربوط به آن تشکیل شده که تحلیلهای متنوعی را بر روی محتوای صوتی و متنی انجام میدهد. نتایج پردازش، با غنیسازی تدریجی ساختارهای XML، ترکیب شده و میتوانند به روشهای مختلف ازطریق اطلاعات زمانبندی موجود در ساختارهای مشروح، به هم متصل شوند. برای پردازش تعدادی از زبانهای طبیعی، که تاکنون چهارده زبان بوده، برای اجزای MMI، امکاناتی نظیر ASR در دسترس است. مدلهایی برای این زبانها توسط آزمایشگاههای سِیل با همکاری سازمانها و مشتریهای شریک وی، توسعه یافتهاند و یک منطقهی فعال توسعه را شکل میدهند.
پردازش صوتی شامل تقطیع و طبقهبندی جریان صوتی ورودی، شناسایی گویندگان (SID)، و/یا جنسیت گوینده و تشخیص خودکار گفتار (ASR) میشود.
سیگنال صوتی، پس از آنکه بهوسیلهی تغذیهکننده به فرمت مناسب تبدیل شد، پردازش شده و به قطعات همگنِ گفتار و غیرگفتار تقطیع میشود. قطعات گفتاری پردازش میشوند تا هویت گوینده مشخص شود و سپس به بخش ASR سپرده میشوند. ASR برای رمزگشاییِ واژگان بزرگ، مستقل از گوینده، چند زبانی، و زمان واقعیِ گفتار پیوسته طراحی شده است و با بهکارگیری مجموعههای مختلفی از مدلها، بهشیوهای چندگذری و همزمان، تشخیص گفتار را انجام میدهد. متعاقباً، بههنجارسازی متن و همچنین پردازش مستقل از زبان انجام میشود تا نتیجهی رمزگشایی نهایی در قالب XML حاصل شود. جزء ASR مستقل از زبان بوده و میتواند با مدلهای متنوعی که برای انتخابهای مختلف زبان و پهنای باند ساخته شدهاند، اجرا شود.
پردازش متن شامل بههنجارسازی و پردازش خاص زبان متن (برای متونی که خروجیِ جزءِ ASR هستند یا توسط تغذیهکنندههای متن فراهم شدهاند)، حاشیهنویسی ماهیتهای مشخص نظیرِ و نه صرفاً افراد، سازمانها یا مکانها و تقطیع و طبقهبندی متن بخشها براساس عنوان میشود(ردیابی عنوان). سیستم NED براساس الگوها و همچنین مدلهای آماری بنا شده که حول محور کلمات و ویژگیهای کلمات تعریف شدهاند و در مراحل متعددی اجرا میشود. جزء ردیابی عنوان (TD) ابتدا بخشهای متن را طبق سلسلهمراتب ویژهای از عناوین طبقهبندی میکند و سپس با قرار دادن بخشهای مشابهِ مجاور در یک گروه، داستانهایی منسجم میسازد. مدلهای بهکار رفته برای TD و تقطیع داستانی، براساس ماشینهای بُردار پشتیبانیِ (SVM) دارای شالودهی خطی، بنا شدهاند.
پردازش بصری در حال حاضر شامل ردیابی و شناسایی چهرهها و همچنین متن درج شده در سیگنال ویدیویی است. اینها، اطلاعات استخراج شده از جریان صوتی را تکمیل میکنند. (تمامی اجزای پردازش بصری از نوع شخص ثالث هستند که با همکاری شرکا توسعه یافته و در سیستم MM ادغام شدهاند). درخصوص تشخیص چهره، چهرهها در ابتدا مکانیابی میشوند و سپس یک مرحلهی بازشناسی روی آنها انجام میگیرد. اطلاعات زمانی موجود، با اجرای یک دنبالکننده و انجام بازشناسی روی مکانهای تصویر شناختهشده، بهکار گرفته میشوند.
شناخت کاراکتر نوری (OCR) بر روی صفحه نمایش، هریک از فریمهایی را پردازش میکند که از جریان ویدیوی زنده در فواصل منظم استخراج میشود. نواحی پایداری که احتمال دارد حاوی کاراکترهایی باشند شناسایی و با هم دستهبندی شده و به Tesseract OCR engine داده میشوند که استخراج متن واقعی را انجام میدهد. در مرحلهی پس از پردازش، ردیابیها با استفاده از یک دیکشنری انطباق داده شده و با اعتبارسنجیِ ردیابیِ OCR فیلتر میشوند.
براساس برچسبهای زمانی، خروجیهای XML حاصل از تمامیِ فنآوریهای مختلف باهم ترکیب (آمیخته) میشوند تا یک نتیجهی نهایی حاصل شود که متعاقب آن روی سرور، بارگذاری شده و برای جستجو و بازیابی در دسترس قرار میگیرد.
تمامی پردازشها میتوانند به نحوی سامان یابند که در لحظه رخ بدهند یا برای تأکید بر کیفیت نتایج، از مدت زمان پردازش هزینه کنند. مجموعه ابزارها در قالب فنآوریهای مختلفی ارائه شدهاند تا امکان ایجاد پسوند آسان و اقتباس از مدلها را فراهم آورند.
د. سرور رسانهکاو و مشتری (MMS و MMC)
MMS از سرور واقعی که برای ذخیرهی XML مورد استفاده قرار میگیرد و فایلهای رسانهای تشکیل میشود، بهعلاوهی مجموعهای از ابزارها و واسطهایی که برای بهروزرسانی و جستجو در محتویات پایگاه داده بهکار میروند. MMS بهعنوان قطب مرکزی خدمت میکند که همهی دادههای تولیدشده توسط MMI به آن فرستاده شده و همهی تحلیلها و تصویرسازیها از آن نشأت میگیرد. اجزای ادغام شده در MMI شامل سرور چندرسانهای برای پخش محتوای چندرسانهای، ژئو سرور برای پردازش تصویر نقشه و نمایش منابع دادهی زیربنایی، یک سرور ترجمه (شخص ثالث) برای ترجمههای همزمانِ رونوشتها و سندها، و Oracle 11g که همهی ویژگیهای جستجو و بازیابی را فراهم میسازد. فنآوریهای معناییِ ایجاد شده توسط اُراکل، اساس تمام عملیات درون سیستم MM را تشکیل میدهد.
تمامی تعاملات کاربر ازطریق MMC اتفاق میافتد. MMC مجموعهای از ویژگیها را ارائه میکند که به کاربران اجازه میدهند محتویات دادههای ذخیره شده در MMS را جستجو کرده، با آنها تعامل داشته باشند و آنها را تجسم و بهروزرسانی کنند. کاربران میتوانند جستجو کنند، محتویات را بارگذاری نمایند، درخواست ترجمه بدهند یا حاشیهنویسیهایی را به اسناد ذخیرهشده بیافزایند. اسناد، نتایج و خلاصهی جستجوها میتوانند از زوایای مختلف دیده و دستکاری شوند، قابلیتی که به کاربر اجازه میدهد ابتدا روی جنبههای مربوطه متمرکز شود و مسائل مربوط را بیشتر و جزئیتر کندوکاو کند. میتوان از ترکیب تجسم و جستارها جهت کشف مجموعه دادهها و رسیدن به بینشی عمیقتر بهره گرفت.
مکانهای ردیابیشده در اسناد میتوانند ازطریق مختصات جغرافیایی در نقشهای ترسیم شوند. روابط میان چیزهای ردیابیشده میتواند ازطریق نمودار رابطهای، به تصویر درآمده و مورد کندوکاو قرار گیرد. روند مشاهده، اشخاص را با رخدادها درطول زمان مربوط میسازد، و بهاین ترتیب امکان مشاهدهی رفتار زمانی آنها را فراهم میآورد. یک مشاهدهی گروهی اشخاص را با منابعی که به آنها اشاره کردهاند مرتبط میسازد، و درنتیجه امکان مقایسهی گزارشها با عناوین یا رخدادهای واحد را ایجاد میکند. بدین ترتیب ممکن است پیچش و زوایای گزارشها بیرون کشیده شود و با کشف دادههای متضاد، مقاصد پنهان خود را نشان دهند. اطلاعات برگرفته از هستیشناسی برای گسترش دادن دامنهی واژگان جستجو به واژگان معناشناسی، جستجوها را اصلاح و هدایت کرده و نتایج جستار را ارائه میکنند. نتایج جستارها طبق نوع سند ارائه میگردد. مثلاً برای اسناد صوتی/تصویری، علاوهبر رونوشت هماهنگ با زمان، اسامی گویندگان یا اشخاصِ شناسایی شده در تصویر نیز نمایش داده میشود و پخش همزمانِ محتوای صوتی و تصویری صورت میگیرد. برای اسناد متنی، متن (استخراجشده) و هر نوع سند مربوطه (فایل PDF برای محتوای وب) نمایش داده میشود.
برای مقاصد دیدهبانی، یک واسطهی بیشتر، یعنی اتاق بحران آزمایشگاههای سیل، در دسترس قرار دارد که امکان دیدهبانی همزمان، اعلام خطر و جستجوی اطلاعاتِ ورودی زندهی تلویزیونی را فراهم میسازد.
در تنظیمات معمول، MMIهای متعددی (تا صدها عدد) که با هم روی منابع و کانالهای مختلف کار میکنند، بهصورت مداوم به گردآوری دادههای ورودی مشغولند؛ درحالیکه در همان زمان، تحلیلگران ازطریق MMCهای متعدد به MMS متصل هستند.
- جستجوهای نمونهای
زمانی که در پاییز سال ۲۰۱۱ سیل به طور کامل پایتخت تایلند را فرا میگرفت، چالش اصلی، ارزیابی کردن بهروز و صحیح شرایط بود. با درنظر گرفتن سردرگمی که اغلب در چنین شرایط بحرانی مستولی میشود، این دست اطلاعات برای برنامهریزی و راهاندازی عملیات امدادرسانی ضروری است. این نکته که ناو هواپیمابر نیروی دریایی آمریکا در این منطقه بیکار و سرگردان مانده بود و سپس بدون هیچ فعالیتی محل را ترک کرد، ابعاد فشار بالقوهی دسترسی نداشتن به اطلاعات مناسب را نشان میدهد. از سوی دیگر، در همان زمان، اطلاعات کاملاً دقیقی، از سوی رسانههای خبریِ پیشروی حاضر در منطقه، بر روی صفحات وب در دسترس بود.
«این که ارتش آمریکا دربارهی جهتگیری دولت تایلند نسبت به کمک خود دچار سردرگمی شده و درنتیجه ناو هواپیمابر را برگردانده بود کاملا صحت دارد، اما باز هم یک کشتی و دو هلیکوپتر در صورت نیاز به کمک، برای ما باقی گذاشته بود.»
فرضاً، اطلاعات لازم در زمان درست و با کیفیت مناسب، در اختیار تصمیمگیران قرار گرفته است. متأسفانه این نوع سردرگمی اطلاعاتی به مثال بالا محدود نمیشود بلکه در شرایط بحرانی بسیار فراگیر است و در موارد زیادی میتواند منجر به وحشت شود. مثال جدیدتری نشان میدهد که در حال ظهور، تشخیص الگوهای بحث تا چه اندازه ضروری است.
در مثال خود فرض میکنیم که منبع اطلاعاتی اولیهی ما، از رسانهی سنتی به خصوص از یک روزنامهی محلی گرفته شده است. مقالهی روزنامه درمورد وقوع زمینلرزهای در نزدیکی شهر راونای ایتالیا به ما هشدار میدهد. حالا با این اطلاعات میتوانیم منابع بیشتری مثل توییتر را جستجو کنیم. در میان توییتهای یافته شده، مورد زیر بسیار جالب توجه است، چراکه لینکی به صفحه وب مربوط به سونامی را شامل میشود:
دنبال کردن این لینک و انجام بررسیهای بیشتر، بهسرعت نشان میدهد که ترس از سونامی در محدودهی اطراف راونا در حال رشد است.
در علم نرمافزار، به جزء نرمافزاری قابل استفادهی مجدد گفته میشود که برای فروش یا پخش رایگان توسط یک نهاد بهجای فروشندهی اصلی پایگاه توسعه ، ایجاد شده است. (م.)

شکل ۲ اسکرین شاتی از Tocus.it
در شرایط تصمیمگیری، تأکید بر پیامهایی نظیر توییت آرامشبخش زیر، که به کمکردن تنش در بحثی بسیار داغ کمک میکنند، خالی از لطف نیست:
وقتی فهمیدیم که اطلاعات ارزشمندی در دسترس است، گام بعدی رسیدن به درک بهتری از شرایط با استخراج روابط در یک نمودار رابطهای است.
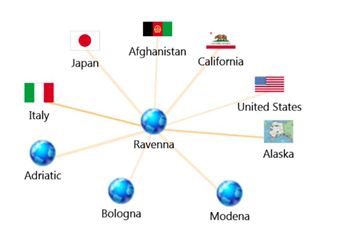
شکل ۳ نمودار رابطهای
همانطور که در نمودار بالا دیده میشود، بهوضوح میتوان میان مناطق زمینلرزه در ایتالیا و تصویر جهانی، روابطی برقرار کرد. از آمارهای موجود میتوان به درک بهتری نسبت به این مسئله رسید که آیا بحث مبتنی بر توییتر مثل مورد بالا، یک رخداد منفرد و مجزاست یا اینکه درواقع فعالیت پایداری را موجب میشود.

شکل ۴ نمودار روند کار
نمودار بالا فراوانی تعداد دفعاتی را نشان میدهد که در اسناد به اشخاص در طول زمان اشاره شده است و تأیید میکند که هیچ وحشت پایداری توسط گزارشهای رسانهای و بحثهای توییتر آغاز نشده است، چراکه میزان فعالیت آنها، تنها به یک روز محدود شده است.
در مواقعی که میبایست به منطقهی فاجعهزده امداد و تجهیزات پزشکی رساند، دانستن این نکته که اوضاع آرام است و هیچ وحشت و نگرانی در برنامهریزی و انجام عملیات امدادرسانی وجود ندارد، ضروری است.
- مزایای بالقوه
یکی از مهمترین درسهایی که از تجاربمان درمورد سیستم خود آموختیم، این است که هرچند اطلاعات در دسترس قرار دارند اما چالش اصلیِ آماده کردن آنها جهت استفادهی تصمیمگیرندگان انسانی، هنوز پابرجاست. کاهش سیل اطلاعات و آشفتگیِ شایع در اغلبِ موقعیتهای بحرانی با جستجوی هدفمند و دربرگیرندهی منابع چند زبانی و چند رسانهای، میتواند منجر به بهبود چشمگیر اساس تصمیمگیریها و واکنش بهموقع شود. این نکته همچنین به مستندسازی و توجیه علت گرفته شدن یک تصمیم، یاری میرساند.
ترجمان نکتهی فوق در مثال ما، معادلِ توانایی کاهش دادن تعداد سناریوهای بالقوهای است که عملیات تسکین فاجعه، با آن مواجه خواهد بود. در مورد مذکور این بدان معناست که وحشت در وضعیت موجود میتواند از بین برود و درنتیجه واحدهای مجری قانون و پاسخ نظامی میتوانند بر کمکهای اولیه و وظایف مهندسی خویش تمرکز کنند. آگاهی نیروهای تسکین فاجعه (آمبولانسها و آتشنشانها) از اینکه وارد منطقهای آرام و پایدار خواهند شد، بدون شک ازلحاظ روانی تأثیر مثبتی بر آنها خواهد گذاشت.
- دورنما و نتیجهگیری
با گسترش سیستم MM و آزموده شدن آن در همکاری با سازمانهای دولتی متعدد، در حال حاضر در جایگاهی قرار داریم که میتوانیم با سیستمهای برنامهریزی و پشتیبانی از مأموریت در مواقع اضطراری و مدیریت بحران، همکاری و رابطهی نزدیکتری داشته باشیم. جالبترین پرسشهای جستجو درمورد این همکاری، احتمالاً در حوزهی توسعهی روابط کارآمد، مدل دادهها و معناشناسی خواهد بود. در پروژههای پژوهشی آینده، از نقطهنظری عملی به پرسشهای تکنیکی و سازمانیِ مربوط به همکاری میان واحدهای مختلف امداد، توسط نویسندگان پرداخته خواهد شد.
این مطلب ترجمهی مقالهای تحت عنوان Open Source Intelligence in Disaster Management است که در کنفرانس اطلاعات و امنیت اطلاعاتی ۲۰۱۲ اروپا ارائه شده بود.
استفاه از مطالب فوق با ذکر منبع (سایت جامع) آزاد است.
ما را در شبکههای اجتماعی دنبال کنید.
دیدگاه خود را ارسال کنید...